
Dec 02, 2025
-
By Julia
![]() AI Summary By Kroolo
AI Summary By Kroolo
The era of AI has just begun and every possible industry is grooming under its umbrella. Did you know that 60% of repetitive data-management tasks will be automated by 2026?
Further, the data management market size under the influence of AI has touched USD 30.84 billion in 2025 marking its potential growth to reach USD 238.31 billion 2035.
This makes one thing clear: organizations with manual sprawling, unstructured data ecosystems risk missing out on the data-modernization wave. But before we talk about AI-powered data modernization, let’s clarify something fundamental—what kind of data are we really talking about?
This blog will guide you through everything you need to know: the different types of data, how organizations should manage them, and the AI-driven strategies you need to keep your data streamlined, accessible, and future-ready.

Organizations—whether small startups or large enterprises—generate and manage vast amounts of data every day. Broadly, this information falls into two primary categories: structured data and unstructured data.
According to industry analysis by AltexSoft, the world is projected to generate 394 zettabytes of data by 2028—a staggering volume represented by a number with 21 zeros. Even more compelling is the fact that 80% to 90% of all data created, captured, and stored globally is unstructured, underscoring the growing complexity of information management.
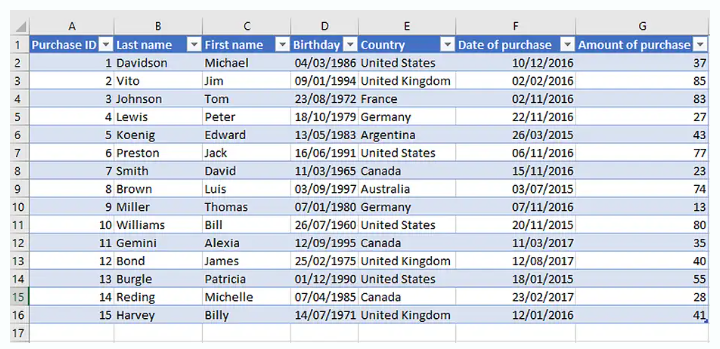
Structured data generally refers to information organized into a predefined format—usually stored within fixed fields in a file, record, or directory. This type of data typically resides in relational databases (RDBMS) and is composed of well-defined values such as numbers, categories, or text entries.
With the rise of AI agents, managing, processing, and distributing structured data has become more seamless. Intelligent agents can now automate data handling tasks, ensure consistency across systems, and deliver insights with precision, setting the foundation for deeper exploration into what structured data is and why it matters in modern data ecosystems.
Customer Database Table
Sales Transaction Record
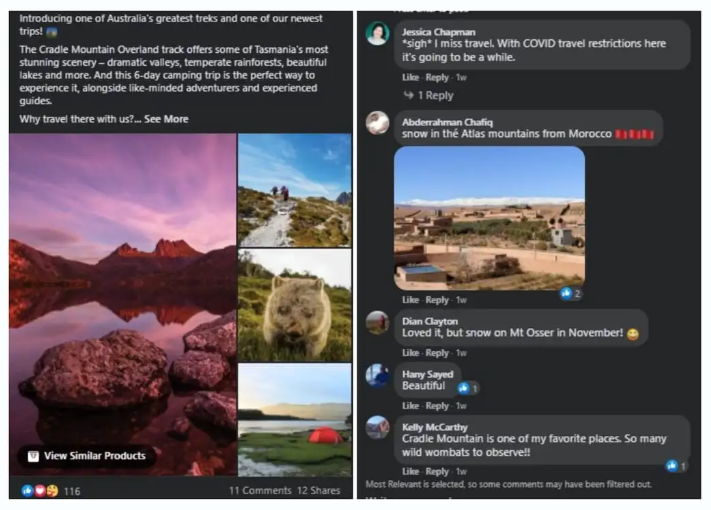
Unstructured data refers to information that does not follow a fixed format. It is human-generated, rich in context, but difficult for traditional systems to store, categorize, or search without AI.
The major examples of unstructured data are social media activities from users, rich media, texts, video files, etc. The globe is loaded with around 80% and above unstructured data from all the sources. It clearly indicates that organizations are not putting efforts in organizing the data and cutting loose on valuable business insights.
Customer Support Email
Social Media Comment
Video or Audio Recording
Semi structured form of data means the partially managed data. It involves certain elements that can distinguish semantic elements & implement data in hierarchies but it is separate from the tabular representation in relational databases. Such type of structuring is known as self-describing.
The best suitable example of semi-structured data is XML, JSON, etc. which is majorly utilized by the next-gen databases such as MongoDB and Couchbase.

Here is an overview of the structured and unstructured data.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
These data types differ fundamentally in organization, analysis, and usage, impacting how businesses manage and derive insights from information assets effectively.
Structured data is clearly defined data in a structure living in rows and columns, while unstructured data is usually stored in its native format without predefined models. Structured data maps into predetermined fields, whereas unstructured data remains undefined until processed for specific analytical purposes.
Structured data is often quantitative data consisting of hard numbers or things that can be counted, while unstructured data is categorized as qualitative data. Customer relationship management systems contain quantitative structured data, while customer surveys and social media interactions provide qualitative unstructured insights.
Businesses often store structured data in data warehouses and unstructured data in data lakes. Data warehouses serve as endpoints for ETL pipelines with structured information, while data lakes function as limitless repositories storing data in original formats, accommodating massive volumes of raw information.
Structured data is easy to search for both data analytics experts and algorithms, while unstructured data is intrinsically more difficult to search and requires processing. Structured data analysis uses regression, classification, and clustering methods, whereas unstructured data demands advanced techniques like data mining and machine learning algorithms.
Structured data is usually stored in a relational database, while the best fit for unstructured data is non-relational, or NoSQL, databases. SQL manages structured data efficiently without advanced coding, while NoSQL databases handle unstructured data's flexible, varied formats more effectively.
Effective metadata implementation enables better organization, discoverability, and governance across different data types throughout enterprise systems.
Metadata uses tags and semantic markers to identify specific data characteristics and scale data into records and preset fields. This enables semi-structured data to be cataloged, searched, and analyzed more efficiently than completely unstructured information, facilitating integration and web scraping operations across platforms.
Global data governance laws require firms to know exactly what is being held within their unstructured data and whether it contains personally identifiable information. Proper metadata design helps organizations track data lineage, ensure regulatory compliance, and maintain data quality standards across structured and unstructured datasets.
Organizations must strategically manage data refresh cycles and storage infrastructure to optimize performance while controlling escalating costs.
Businesses must refresh storage infrastructure every three to five years and include all of their cool unstructured data in this process integrate. Companies must also consider migration costs and secondary storage required to support backups, making strategic planning essential for long-term data management efficiency.
Current estimates show that most business data is cool data (data that has not been accessed for 30 days), which clogs up expensive hard drives. Efficient management through cloud, tape, or secondary storage solutions optimizes performance and lowers costs, preventing primary storage systems from becoming overwhelmed with infrequently accessed information.

Artificial intelligence transforms how organizations process massive data volumes, enabling automated insights extraction, pattern recognition, and intelligent decision-making across structured and unstructured datasets.
AI can quickly process large volumes of data, which is a key capability for organizations wanting to transform massive amounts of unstructured data into actionable insights. Machine learning models identify patterns, anomalies, and trends within complex datasets automatically.
With natural language processing, AI algorithms can sift through unstructured data to find patterns and make real-time predictions or recommendations. NLP extracts meaning from emails, social media content, customer reviews, and documents, converting qualitative information into quantitative business intelligence effectively.
Organizations can incorporate analytical models into existing dashboards or application programming interfaces to automate decision-making processes. AI-driven predictions enable proactive responses to market changes, customer behaviors, and operational challenges, reducing manual intervention and improving response times significantly.
AI technologies process video, audio, and image files to extract valuable information previously inaccessible through traditional methods. Computer vision, speech recognition, and sentiment analysis tools convert multimedia unstructured data into structured insights, enabling comprehensive analysis across all data formats.
AI automates metadata tagging and classification processes, improving data discoverability and governance compliance. Automated systems identify data types, assign appropriate tags, track data lineage, and flag sensitive information, reducing manual effort while maintaining accuracy and regulatory adherence.